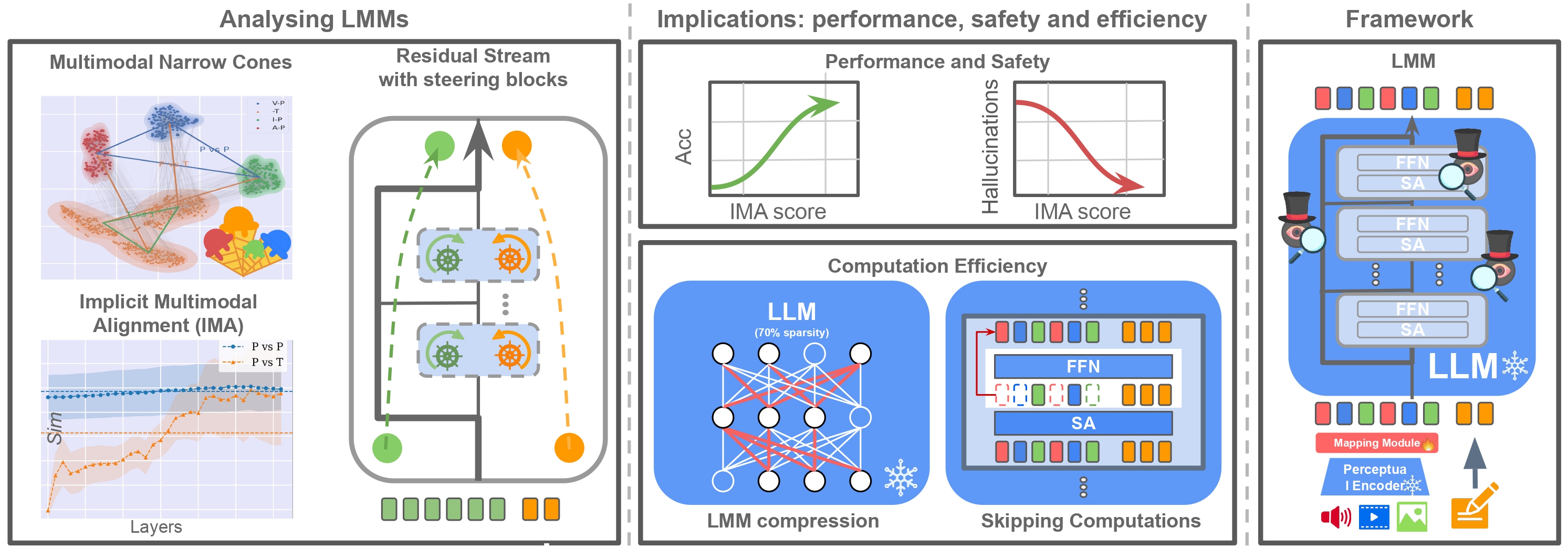
Large Language Models (LLMs) have demonstrated impressive performance on multimodal tasks, without any multimodal finetuning.
They are the de facto building block for Large Multimodal Models (LMMs), yet, we still lack a proper understanding of their success.
In this work, we expose frozen LLMs to image, video, audio and text inputs and analyse their internal representation with the attempt to
understand their generalization beyond textual inputs.
Large Language Models (LLMs) are able to generalize to multimodal inputs.
Specifically, with minimal computation resources (i.e. amouting to training only a linear layer),
it is possible to feed a frozen LLM, with multimodal inputs, so that the model can reason and chat about an image,
video or audio. In this work, we are curios about this observation and try to investigate the following questions:
This works led to the following findings:
Thse findings have several implications:
@article{shukor2024implicit,
title={Implicit Multimodal Alignment: On the Generalization of Frozen LLMs to Multimodal Inputs},
author={Shukor, Mustafa and Cord, Matthieu},
journal={arXiv preprint arXiv:2405.16700},
year={2024}
}